

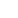
Trying to define data driven journalism
 A decade ago the use of extensive databases for reporting was difficult, time-consuming and expensive. Databases were mainly used by investigative journalists. The situation is very different today. Entire collections of data are now available online, often for free. They are easy to browse thanks to open source navigation tools. Lorenz Matzat wrote this guest blog post on data driven journalism.
A decade ago the use of extensive databases for reporting was difficult, time-consuming and expensive. Databases were mainly used by investigative journalists. The situation is very different today. Entire collections of data are now available online, often for free. They are easy to browse thanks to open source navigation tools. Lorenz Matzat wrote this guest blog post on data driven journalism.
The Internet generates many buzzwords – slogans that resonate for a certain time and then either take root or disappear again. Data driven journalism (DDJ) is a term that has been pervading the Web with increasing frequency since 2009. In March of that year, British newspaper “The Guardian” started a Datablog on its website; it is embedded in a “Datastore” and can be considered to be the most important reference for DDJ to date.
But in fact, DDJ started even earlier, in 2006: An article by Adrian Holovaty called “A fundamental way newspaper sites need to change“ is thought to be a kind of a manifesto for DDJ. Holovaty wrote that much information already exists in a structured form (data sets) or that could be usefully stored as such. Using the story of a local fire as an example, he pointed out that there are certain attributes that remain the same for all fires. We have the same questions about the facts – the “five W’s and one H” that form the basis of gathering information: Where, when, how many affected, injured, dead, how many firemen at the scene, etc. According to Holovaty, newspaper editorial offices could develop event databases using consistently structured data that can be used offline for in-house research, but also online for Internet users and audiences – for example a map could portray the locations of various fires and be filtered according to certain criteria.
So what is new about data-driven journalism?
There’s nothing new about researching data records, for example statistics. The same can be said about computer-assisted reporting (CAR) which has been standard practice for decades. But DDJ combines research and its form of publication: Software is used to link together and analyze one or more machine-readable data sets, resulting in coherent, informative meaning that wasn’t evident beforehand. This information is presented as static or interactive visualization along with explanations of context and data origin (ideally the data record is published too). As appropriate, the data source can be accompanied by commentary (text, audio or video). If the data is not machine-readable (e.g. takes the form of hundreds of thousands of e-mails), users could be encouraged to contribute to the research process, also known as crowdsourcing (see for example Investigate your MP’s expenses).
The changing role of journalists
DDJ presumes that journalists are willing to reveal their sources of research and share them with media consumers. This means that the source becomes verifiable but also reusable. This form of empowering users is part of the principle of Creative Commons, but also of the Open Access approach in the field of science, where it’s common for databases to be published alongside research results (which can for example raise the quality of peer-reviewing, a process of self-regulation and evaluation among professionals working in the same field). In addition to this, data journalists not only have to be open to technological aspects of the Web; they also have to master them. Data research can also mean obtaining data that wasn’t initially intended for the public. “Data mining” and “Web scraping” to access raw data are terms used in this context. It follows that journalists should be computer literate and/or editorial offices should hire professional programmers.
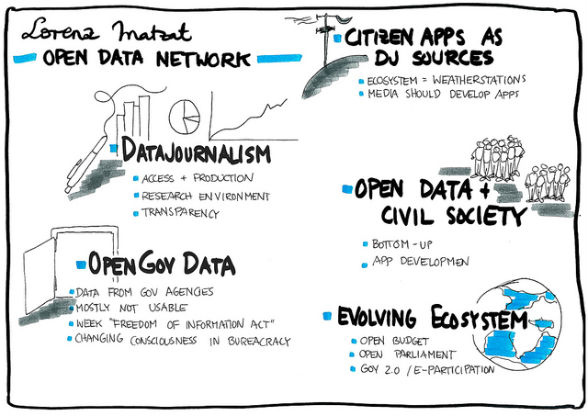
Borderline cases
A matter up for debate is to what extent data visualization is a part of DDJ. Producing and using infographics is not a new area; whether purely static visualization of data (bar charts, etc.) can be counted toward DDJ depends on the extent to which other DDJ criteria have been met (such as the publication of data sources). By contrast, interactive graphics such as mashup maps are certainly classified as DDJ.
But can it still be called journalism if there are no longer journalists and instead only completely automated Web software tools retrieving, processing and reproducing databases? Some people consider projects like TheyWorkforYou.com by mySociety.org to be a part of DDJ.But where is the boundary between information services and reporting? Maybe the term here should be “machine journalism”.
Additional value
Data journalism is based on the principles of a free and open cyber culture: free access to knowledge, information sharing and cooperation. Automated retrieval, analysis and processing of partly monumental data sets from the realms of politics, administration, economic and science (open data) can bring qualitative added value by expanding understanding and coverage of society and nature. It can reveal correlations that weren’t previously evident. Given the success of Wikileaks, the role data can play for investigative journalism needs no further explanation here.
In addition, DDJ can provide researchers and users with easy-to-use tools to dig deeply into data sources. DDJ can also facilitate collective and collaborative research in cases where software can not (yet) meaningfully interpret data sets.
With DDJ, the role of (some) journalists will continue to change. That also means that the established media’s ongoing struggle with the Web will continue. That has something to do with the self-image media producers have of themselves. The digital democratization of media production challenges the positions of conventional journalists. This can be seen in the debate about bloggers versus “real” journalists.
A central device of contemporary society is hierarchy of information – those who can withhold information, those who maintain interpretative predominance of important events, and those who can circulate their interpretation with the greatest and most extensive authority.
Guest blog post by Lorenz Matzat, first published in the Open Data Network , April 13, 2010 (in German).
Translation: Ariane Missuweit (df)








![]()
Feedback